Python Tutorial Part III--Clean OptionMetrics
April 7, 2017 | Michael Gong
1. Clean OptionMetrics dataset
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
raw = pd.read_csv('5Firms.csv.zip',parse_dates=[2,3])
raw.drop(columns=['secid','issuer','exercise_style','last_date'],inplace=True)
raw.head(5)
|
date |
exdate |
cp_flag |
strike_price |
best_bid |
best_offer |
volume |
open_interest |
imvol |
delta |
optionid |
ticker |
index_flag |
midquo |
| 14 |
2012-01-03 |
2012-01-21 |
C |
34.000 |
9.300 |
10.250 |
0 |
0 |
0.529 |
0.988 |
70433772 |
COF |
0 |
9.775 |
| 15 |
2012-01-03 |
2012-01-21 |
C |
35.000 |
8.600 |
9.200 |
0 |
1237 |
0.666 |
0.948 |
45658102 |
COF |
0 |
8.900 |
| 16 |
2012-01-03 |
2012-01-21 |
C |
36.000 |
7.350 |
8.300 |
0 |
10 |
0.515 |
0.965 |
67966062 |
COF |
0 |
7.825 |
| 17 |
2012-01-03 |
2012-01-21 |
C |
37.000 |
6.800 |
7.050 |
0 |
4 |
0.550 |
0.929 |
70433773 |
COF |
0 |
6.925 |
| 18 |
2012-01-03 |
2012-01-21 |
C |
38.000 |
5.850 |
6.000 |
0 |
589 |
0.481 |
0.921 |
54279804 |
COF |
0 |
5.925 |
<class 'pandas.core.frame.DataFrame'>
Int64Index: 4467804 entries, 14 to 5719675
Data columns (total 14 columns):
date datetime64[ns]
exdate datetime64[ns]
cp_flag object
strike_price float64
best_bid float64
best_offer float64
volume int64
open_interest int64
imvol float64
delta float64
optionid int64
ticker object
index_flag int64
midquo float64
dtypes: datetime64[ns](2), float64(6), int64(4), object(2)
memory usage: 511.3+ MB
# change the implied volatility name (it's too long)
raw.rename(columns={'impl_volatility': 'imvol'}, inplace=True)
# transform the strike price and calculate the mid quotes
raw['strike_price'] = raw['strike_price'] / 1000.0
raw['midquo'] = (raw['best_bid'] + raw['best_offer']) / 2
raw.head(5)
|
date |
exdate |
cp_flag |
strike_price |
best_bid |
best_offer |
volume |
open_interest |
imvol |
delta |
optionid |
ticker |
index_flag |
midquo |
| 14 |
2012-01-03 |
2012-01-21 |
C |
0.034 |
9.300 |
10.250 |
0 |
0 |
0.529 |
0.988 |
70433772 |
COF |
0 |
9.775 |
| 15 |
2012-01-03 |
2012-01-21 |
C |
0.035 |
8.600 |
9.200 |
0 |
1237 |
0.666 |
0.948 |
45658102 |
COF |
0 |
8.900 |
| 16 |
2012-01-03 |
2012-01-21 |
C |
0.036 |
7.350 |
8.300 |
0 |
10 |
0.515 |
0.965 |
67966062 |
COF |
0 |
7.825 |
| 17 |
2012-01-03 |
2012-01-21 |
C |
0.037 |
6.800 |
7.050 |
0 |
4 |
0.550 |
0.929 |
70433773 |
COF |
0 |
6.925 |
| 18 |
2012-01-03 |
2012-01-21 |
C |
0.038 |
5.850 |
6.000 |
0 |
589 |
0.481 |
0.921 |
54279804 |
COF |
0 |
5.925 |
# drop contracts with NaN implied volatility or Nan delta
raw.dropna(subset=['imvol'], how='any', inplace=True)
raw.dropna(subset=['delta'], how='any', inplace=True)
# Exclude implied volatility above 150%
raw = raw[raw['imvol'] < 1.5]
# Exclude price below 0.05
raw = raw[raw['best_offer'] > 0.05]
raw.head(5)
|
date |
exdate |
cp_flag |
strike_price |
best_bid |
best_offer |
volume |
open_interest |
imvol |
delta |
optionid |
ticker |
index_flag |
midquo |
| 14 |
2012-01-03 |
2012-01-21 |
C |
0.034 |
9.300 |
10.250 |
0 |
0 |
0.529 |
0.988 |
70433772 |
COF |
0 |
9.775 |
| 15 |
2012-01-03 |
2012-01-21 |
C |
0.035 |
8.600 |
9.200 |
0 |
1237 |
0.666 |
0.948 |
45658102 |
COF |
0 |
8.900 |
| 16 |
2012-01-03 |
2012-01-21 |
C |
0.036 |
7.350 |
8.300 |
0 |
10 |
0.515 |
0.965 |
67966062 |
COF |
0 |
7.825 |
| 17 |
2012-01-03 |
2012-01-21 |
C |
0.037 |
6.800 |
7.050 |
0 |
4 |
0.550 |
0.929 |
70433773 |
COF |
0 |
6.925 |
| 18 |
2012-01-03 |
2012-01-21 |
C |
0.038 |
5.850 |
6.000 |
0 |
589 |
0.481 |
0.921 |
54279804 |
COF |
0 |
5.925 |
# calculate maturity
raw['maturity'] = ((raw['exdate'] - raw['date']) / np.timedelta64(1, 'D')).astype(int)
# Exclude contracts with maturity longer than 240 days and shorter than 7 days
raw = raw[(raw['maturity'] <= 360) & (raw['maturity'] >= 7)]
raw.head(5)
|
date |
exdate |
cp_flag |
strike_price |
best_bid |
best_offer |
volume |
open_interest |
imvol |
delta |
optionid |
ticker |
index_flag |
midquo |
maturity |
| 14 |
2012-01-03 |
2012-01-21 |
C |
0.034 |
9.300 |
10.250 |
0 |
0 |
0.529 |
0.988 |
70433772 |
COF |
0 |
9.775 |
18 |
| 15 |
2012-01-03 |
2012-01-21 |
C |
0.035 |
8.600 |
9.200 |
0 |
1237 |
0.666 |
0.948 |
45658102 |
COF |
0 |
8.900 |
18 |
| 16 |
2012-01-03 |
2012-01-21 |
C |
0.036 |
7.350 |
8.300 |
0 |
10 |
0.515 |
0.965 |
67966062 |
COF |
0 |
7.825 |
18 |
| 17 |
2012-01-03 |
2012-01-21 |
C |
0.037 |
6.800 |
7.050 |
0 |
4 |
0.550 |
0.929 |
70433773 |
COF |
0 |
6.925 |
18 |
| 18 |
2012-01-03 |
2012-01-21 |
C |
0.038 |
5.850 |
6.000 |
0 |
589 |
0.481 |
0.921 |
54279804 |
COF |
0 |
5.925 |
18 |
# save the cleaned raw data, because it is time-consuming to processing, next time we just need to load it
hdf = pd.HDFStore('hdf.h5')
hdf['raw'] = raw
hdf.close()
# if next time we start from here
# hdf = pd.HDFStore('hdf.h5')
# raw = hdf['raw']
# hdf.close()
2. Some summary statistics
# select variable we want
clean = raw[['date', 'ticker', 'imvol', 'delta', 'maturity', 'cp_flag']].reset_index(drop=True)
clean.head(5)
|
date |
ticker |
imvol |
delta |
maturity |
cp_flag |
| 0 |
2012-01-03 |
COF |
0.529 |
0.988 |
18 |
C |
| 1 |
2012-01-03 |
COF |
0.666 |
0.948 |
18 |
C |
| 2 |
2012-01-03 |
COF |
0.515 |
0.965 |
18 |
C |
| 3 |
2012-01-03 |
COF |
0.550 |
0.929 |
18 |
C |
| 4 |
2012-01-03 |
COF |
0.481 |
0.921 |
18 |
C |
print('stocks ticker:\n',clean['ticker'].unique())
print('maturity range:\n',clean['maturity'].min(),clean['maturity'].max())
print('delta range:\n',clean['delta'].min(),clean['delta'].max())
stocks ticker:
['COF' 'DD' 'XOM' 'INTC' 'SPX' 'UNH']
maturity range:
7 360
delta range:
-0.999934 0.999999
stats = clean.groupby(['ticker','cp_flag'])[['imvol','delta']].describe()
stats
|
|
imvol |
delta |
|
|
count |
mean |
std |
min |
25% |
50% |
75% |
max |
count |
mean |
std |
min |
25% |
50% |
75% |
max |
| ticker |
cp_flag |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| COF |
C |
100419.000 |
0.295 |
0.146 |
0.063 |
0.199 |
0.249 |
0.341 |
1.000 |
100419.000 |
0.523 |
0.359 |
0.008 |
0.130 |
0.577 |
0.884 |
1.000 |
| P |
108812.000 |
0.319 |
0.144 |
0.057 |
0.213 |
0.280 |
0.386 |
1.000 |
108812.000 |
-0.372 |
0.340 |
-1.000 |
-0.710 |
-0.240 |
-0.059 |
-0.003 |
| DD |
C |
125769.000 |
0.264 |
0.138 |
0.063 |
0.178 |
0.217 |
0.299 |
0.999 |
125769.000 |
0.553 |
0.366 |
0.008 |
0.146 |
0.639 |
0.917 |
1.000 |
| P |
134941.000 |
0.262 |
0.105 |
0.047 |
0.187 |
0.233 |
0.313 |
0.999 |
134941.000 |
-0.392 |
0.352 |
-1.000 |
-0.760 |
-0.255 |
-0.063 |
-0.004 |
| INTC |
C |
113863.000 |
0.306 |
0.150 |
0.084 |
0.218 |
0.248 |
0.331 |
1.000 |
113863.000 |
0.577 |
0.349 |
0.015 |
0.209 |
0.660 |
0.922 |
1.000 |
| P |
127602.000 |
0.293 |
0.113 |
0.074 |
0.221 |
0.260 |
0.334 |
1.000 |
127602.000 |
-0.505 |
0.359 |
-1.000 |
-0.882 |
-0.514 |
-0.122 |
-0.007 |
| SPX |
C |
1240711.000 |
0.245 |
0.151 |
0.050 |
0.139 |
0.202 |
0.297 |
1.000 |
1240711.000 |
0.674 |
0.361 |
0.001 |
0.373 |
0.869 |
0.970 |
1.000 |
| P |
1344534.000 |
0.259 |
0.135 |
0.033 |
0.157 |
0.233 |
0.326 |
1.000 |
1344534.000 |
-0.251 |
0.328 |
-1.000 |
-0.419 |
-0.066 |
-0.010 |
-0.000 |
| UNH |
C |
86588.000 |
0.280 |
0.133 |
0.076 |
0.204 |
0.236 |
0.303 |
1.000 |
86588.000 |
0.536 |
0.364 |
0.007 |
0.141 |
0.600 |
0.904 |
1.000 |
| P |
92393.000 |
0.290 |
0.118 |
0.066 |
0.213 |
0.255 |
0.333 |
0.999 |
92393.000 |
-0.395 |
0.352 |
-1.000 |
-0.759 |
-0.271 |
-0.058 |
-0.003 |
| XOM |
C |
112332.000 |
0.240 |
0.140 |
0.034 |
0.156 |
0.187 |
0.265 |
1.000 |
112332.000 |
0.535 |
0.358 |
0.006 |
0.148 |
0.601 |
0.889 |
1.000 |
| P |
126483.000 |
0.244 |
0.110 |
0.039 |
0.169 |
0.213 |
0.287 |
0.999 |
126483.000 |
-0.418 |
0.353 |
-1.000 |
-0.796 |
-0.316 |
-0.073 |
-0.003 |
# constant
clean['const'] = 1
# scaled moneyness
clean['delta_n'] = clean['delta']
clean.loc[(clean['cp_flag']=='P'),'delta_n'] = 1 + clean.loc[(clean['cp_flag']=='P'),'delta']
clean['delta_n'] = clean['delta_n'] - 0.5
# scaled maturity
clean['matur_n'] = clean['maturity']/360 - 0.5
# quadratic term of moneyness
clean['delta2'] = clean['delta_n']**2
# interaction between maturity and moneyness
clean['inter'] = clean['delta_n']*clean['matur_n']
clean.head(5)
|
date |
ticker |
imvol |
delta |
maturity |
cp_flag |
const |
delta_n |
matur_n |
delta2 |
inter |
| 0 |
2012-01-03 |
COF |
0.529 |
0.988 |
18 |
C |
1 |
0.488 |
-0.450 |
0.239 |
-0.220 |
| 1 |
2012-01-03 |
COF |
0.666 |
0.948 |
18 |
C |
1 |
0.448 |
-0.450 |
0.201 |
-0.202 |
| 2 |
2012-01-03 |
COF |
0.515 |
0.965 |
18 |
C |
1 |
0.465 |
-0.450 |
0.216 |
-0.209 |
| 3 |
2012-01-03 |
COF |
0.550 |
0.929 |
18 |
C |
1 |
0.429 |
-0.450 |
0.184 |
-0.193 |
| 4 |
2012-01-03 |
COF |
0.481 |
0.921 |
18 |
C |
1 |
0.421 |
-0.450 |
0.177 |
-0.189 |
4. Cross-section regression
import statsmodels.api as sm
4.1 straightforward way
tickers = clean['ticker'].unique()
ticker = tickers[0]
tmp = clean[clean['ticker']==ticker]
dates = tmp['date'].unique()
tmp = tmp[tmp['date']==dates[0]]
tmp.head(5)
|
date |
ticker |
imvol |
delta |
maturity |
cp_flag |
const |
delta_n |
matur_n |
delta2 |
inter |
| 0 |
2012-01-03 |
COF |
0.529 |
0.988 |
18 |
C |
1 |
0.488 |
-0.450 |
0.239 |
-0.220 |
| 1 |
2012-01-03 |
COF |
0.666 |
0.948 |
18 |
C |
1 |
0.448 |
-0.450 |
0.201 |
-0.202 |
| 2 |
2012-01-03 |
COF |
0.515 |
0.965 |
18 |
C |
1 |
0.465 |
-0.450 |
0.216 |
-0.209 |
| 3 |
2012-01-03 |
COF |
0.550 |
0.929 |
18 |
C |
1 |
0.429 |
-0.450 |
0.184 |
-0.193 |
| 4 |
2012-01-03 |
COF |
0.481 |
0.921 |
18 |
C |
1 |
0.421 |
-0.450 |
0.177 |
-0.189 |
exogs = ['const','delta_n','matur_n','delta2','inter']
mB = np.linalg.lstsq(tmp[exogs],tmp['imvol'])[0]
array([ 0.272, 0.176, -0.170, 0.920, 0.054])
4.2 More concise way
def CrossReg(df,exogs):
mod = sm.OLS(df['imvol'],df[exogs]).fit()
ind = pd.MultiIndex.from_product([['params','tvalues'],exogs])
ret = pd.Series(index=ind)
ret.loc['params'] = mod.params.values
ret.loc['tvalues'] = mod.tvalues.values
ret.loc['r2'] = mod.rsquared
return ret
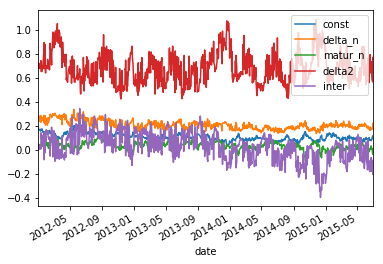
exogs = ['const','delta_n','matur_n','delta2','inter']
mB = clean.groupby(['ticker','date']).apply(lambda x:CrossReg(x,exogs))
mB.loc['SPX']['params'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f2d109103c8>
4.3 Need for speed
4.3.1 Just for coefficients, sequential
def CrossRegSpeed(df,exogs):
mB = np.linalg.lstsq(df[exogs],df['imvol'])[0]
return pd.Series(mB,index=exogs)
mB = clean.groupby(['ticker','date']).apply(lambda x:CrossRegSpeed(x,exogs))
4.3.2 Just for coefficients, parallel
import multiprocessing as mp
from functools import partial
def CrossRegParHelper(ticker):
tmp = DATA[DATA['ticker']==ticker]
mB = tmp.groupby(['date']).apply(lambda x:CrossRegSpeed(x,EXOGS))
mB['ticker'] = ticker
return mB
def CrossRegPar(data,exogs):
global DATA, EXOGS
DATA = data
EXOGS = exogs
pool = mp.Pool(processes=12)
results = pool.map(CrossRegParHelper, tickers)
pool.close()
pool.join()
mB = pd.concat(results)
return mB
mB = CrossRegPar(clean,exogs)
%timeit clean.groupby(['ticker','date']).apply(lambda x:CrossRegSpeed(x,exogs))
8 s ± 33.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit CrossRegPar(clean,exogs)
4.2 s ± 51.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
4.3.3 JIT compilation
clean.sort_values(by=['ticker','date'],inplace=True)
locs = clean.groupby(['ticker','date']).size().values.cumsum()
locs = np.insert(locs,0,0)
mY = clean[['imvol']].values
mX = clean[exogs].values
@nb.jit
def CrossRegJIT(mX,mY,locs):
N = locs.shape[0]
mB = np.zeros((mX.shape[1],N-1))
for i in range(0,N-1):
b = np.linalg.lstsq(mX[locs[i]:locs[i+1]],mY[locs[i]:locs[i+1]])[0]
mB[:,[i]] = b
return mB
mB = CrossRegJIT(mX,mY,locs)
%timeit CrossRegJIT(mX,mY,locs)
702 ms ± 6.65 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
mB = pd.DataFrame(mB.T,index=clean.groupby(['ticker','date']).size().index,columns=exogs)
|
const |
delta_n |
matur_n |
delta2 |
inter |
ticker |
| date |
|
|
|
|
|
|
| 2012-01-03 |
0.272 |
0.176 |
-0.170 |
0.920 |
0.054 |
COF |
| 2012-01-04 |
0.288 |
0.079 |
-0.090 |
1.023 |
-0.263 |
COF |
| 2012-01-05 |
0.288 |
0.160 |
-0.129 |
0.776 |
-0.110 |
COF |
| 2012-01-06 |
0.251 |
0.246 |
-0.149 |
1.189 |
0.076 |
COF |
| 2012-01-09 |
0.267 |
0.176 |
-0.167 |
0.881 |
0.312 |
COF |
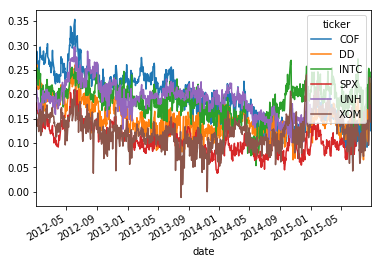
5. Principal Component Analysis
mB.reset_index(inplace=True)
level = pd.pivot_table(mB,index='date',columns='ticker',values='const')
from sklearn import preprocessing
import scipy as sp
def pcaAnalysis(mX, iPC, useCov=1):
if useCov:
# mCov = np.cov(mX, rowvar = 0)
de_meanX = mX - np.tile(np.mean(mX, axis=0), [mX.shape[0], 1])
mCov = np.dot(de_meanX.transpose(), de_meanX) / mX.shape[0]
eigval, eigvec = sp.linalg.eigh(mCov)
eigidx = np.argsort(eigval)
maxidx = eigidx[::-1]
sorted_vec = eigvec[:, maxidx]
mPC = np.dot(de_meanX, sorted_vec)
return mPC[:, 0:iPC], (eigval[maxidx] / np.sum(eigval))[0:iPC]
else:
mCoef = np.corrcoef(mX, rowvar=0)
scaled_X = preprocessing.scale(mX)
eigval, eigvec = sp.linalg.eigh(mCoef)
eigidx = np.argsort(eigval)
maxidx = eigidx[::-1]
sorted_vec = eigvec[:, maxidx]
mPC = np.dot(scaled_X, sorted_vec)
return preprocessing.scale(mPC[:, 0:iPC]), (eigval[maxidx] /
np.sum(eigval))[0:iPC]
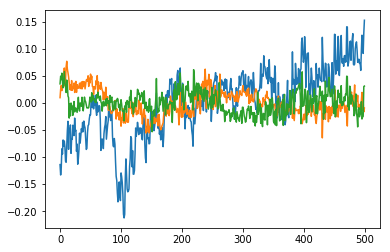
mPC,pct = pcaAnalysis(level.values[:500],3)
pct
array([ 7.22e-01, 9.53e-02, 6.82e-02])
[<matplotlib.lines.Line2D at 0x7f054028cb70>,
<matplotlib.lines.Line2D at 0x7f054028c518>,
<matplotlib.lines.Line2D at 0x7f054028cf28>]